m1 = mean(c(25, 30, 28, 23, 31))
m2 = mean(c(33, 35, 32, 39, 29))
T0 = m2-m1
cat("Różnica_średnich_obu_prób: T0 =", T0)Różnica_średnich_obu_prób: T0 = 6.2Testy permutacyjne wykorzystuje się do weryfikacji istotności różnic zarówno w próbach zależnych
jak i w dwóch niezależnych próbach. Stanowią ważny element przy analizach porównawczych sprawdzając jak zastosowana zmiana wpływa na zmienną. Należy podkreślić, że ich ogromną zaletą jest szeroki zakres zastosowań: w medycynie, gdzie można ocenić stan zdrowia pacjenta przed i po podaniu leku,
w marketingu sprawdzając skuteczność nowej reklamy, czy w ekonomii badając skutki nowo wprowadzonych regulacji w dziale finansów.
Badaniu poddano 10 jabłoni, które podzielono równo na dwie próby.
Pierwszą próbę nazwano próbą kontrolną, gdzie drzewa były podlewane tym samym preparatem
co zawsze. Natomiast w drugiej, nazwanej próbą badawczą, zastosowano inny preparat.
Po miesiącu, zliczono owoce na wszystkich drzewach obu prób i zapisano wyniki:
Próba kontrolna: 25, 30, 28, 23, 31 [jabłek]
Próba badawcza: 33, 35, 32, 39, 29 [jabłek]
Założeniem badania było sprawdzenie, czy, po upływie określonego czasu badania, nowa kuracja spowodowała, że średnia ilość owoców na jabłoniach była większa, niż w próbie kontrolnej.
\(H_0: m_1 = m_2\)
\(H_1: m_1 < m_2\)
\(m_1\) - średnia wyników próby kontrolnej
\(m_2\) - średnia wyników próby badawczej
Wyliczamy różnicę średnich obu prób (\(T_0\))
m1 = mean(c(25, 30, 28, 23, 31))
m2 = mean(c(33, 35, 32, 39, 29))
T0 = m2-m1
cat("Różnica_średnich_obu_prób: T0 =", T0)Różnica_średnich_obu_prób: T0 = 6.2Następnie mieszamy wyniki obu grup, na nowo dzielimy na dwie próby i na nowo liczymy różnicę średnich. Proces ten powtarzamy wielokrotnie.
Istotność testu, czyli wartość p* to prawdopodobieństwo, że przy losowym przemieszaniu wyników (permutacji) otrzymamy różnicę taką samą lub większą niż ta, którą faktycznie zaobserwowaliśmy
w naszym badaniu.
*nazywana również ASL (Average Significance Level)
\(p=P(|T|\ge|T_0|)\)
Do szybszego obliczenia wartości p, można posłużyć się programem R, używając funkcji \(t.test()\). Niech prawdziwe będzie założenie poziomu istotności \(\alpha = 0,05\).
m1 = c(25, 30, 28, 23, 31)
m2 = c(33, 35, 32, 39, 29)
t.test(m1, m2, alternative = "less", conf.level=0.05)$p.value[1] 0.01231701Wartość p jest mniejsza od przyjętego poziomu istotności, zatem należy odrzucić hipotezę \(H_0\) na rzecz hipotezy alternatywnej, głoszącej, że średnia liczba owoców na jabłoniach po zastosowaniu nowej kuracji była większa, aniżeli w próbie kontrolnej.
W poniższych zadaniach przyjęto poziom istotności: \(\alpha = 0.05\).
Oto kilka pakietów w programie R:
#install.packages("resample")
library(resample)
set.seed(150)
x1 = c(0.85, 0.92, 0.88, 0.79, 0.95, 0.90)
x2 = c(0.14, 0.12, 0.18, 0.08, 0.19, 0.10)
permutationTest2(data = x1, statistic = mean, data2 = x2, alternative = "greater")$stats$PValue[1] 0.0011p.value < \(\alpha =0.05\). Należy odrzucić \(H_0\) na rzecz \(H_1\).
#install.packages("coin")
library(coin)
x = c(9, 6, 11, 15, 12, 14, 5, 8)
próbka = factor(c(rep("1", 3), rep("2", 5))) #Próbka "1" zawiera 3 wartości x. Próbka "2" zawiera 5 wartości x.
frame = data.frame(próbka,x)
oneway_test(x ~ próbka, data = frame)
Asymptotic Two-Sample Fisher-Pitman Permutation Test
data: x by próbka (1, 2)
Z = -0.80578, p-value = 0.4204
alternative hypothesis: true mu is not equal to 0p.value > \(\alpha = 0.05\). Brak podstaw do odrzucenia \(H_0\).
#install.packages("EnvStats")
library(EnvStats)
set.seed(150)
x1 = c(5, 6, 11, 12, 1, 2, 3)
x2 = c(7, 10, 15, 13, 12, 8, 9, 15)
x = twoSamplePermutationTestLocation(x1, x2,alternative = "two.sided")
x$p.value[1] 0.017p.value < \(\alpha =0.05\). Należy odrzucić \(H_0\) na rzecz \(H_1\).
plot(x, main = "Test permutacyjny dla dwóch prób oparty na różnicy średnich")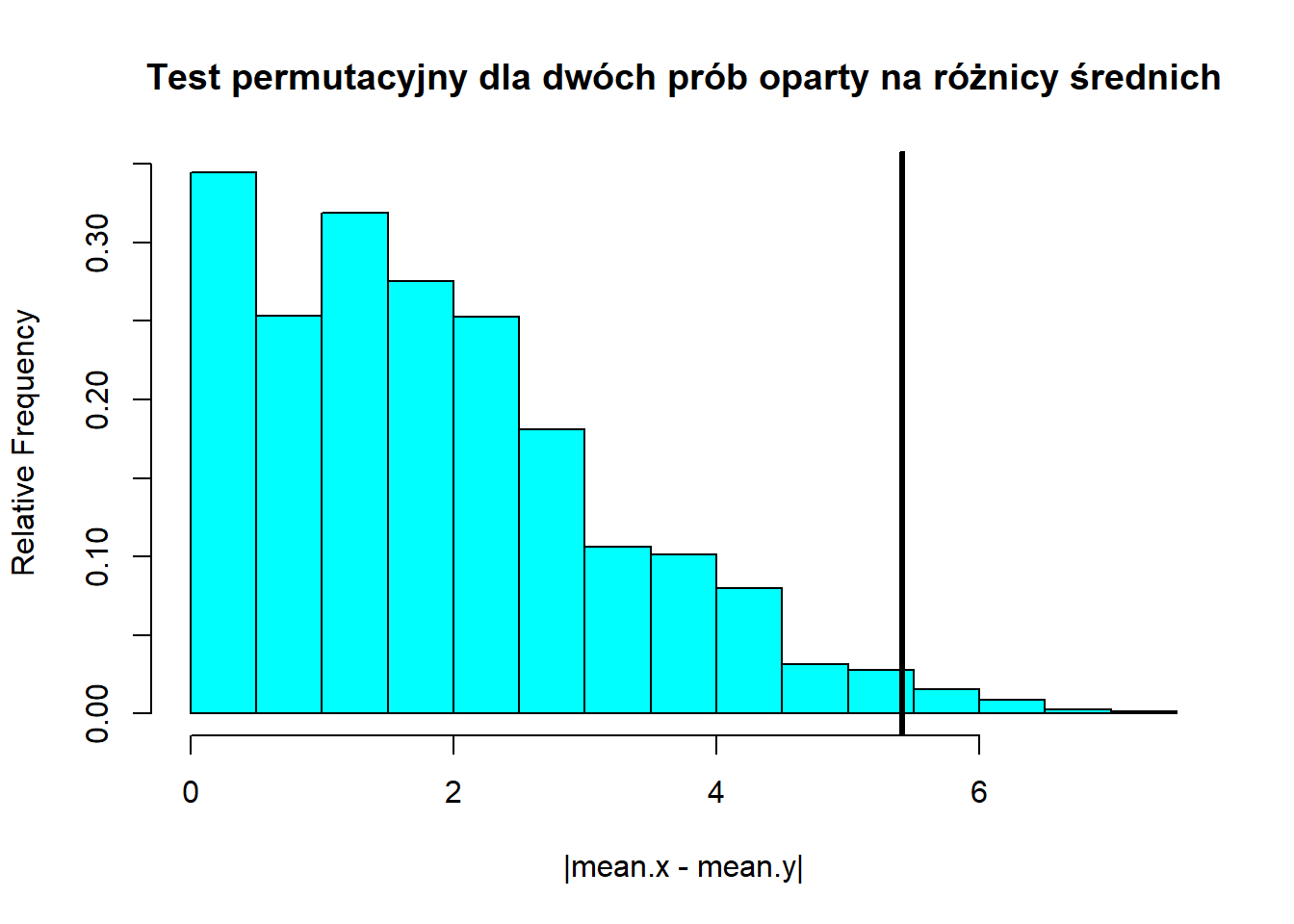
#install.packages("EnvStats")
library(EnvStats)
x = c(7, 10, 15, 13, 12, 8, 9, 4)
pr = oneSamplePermutationTest(x, mu = 11,
alternative = "greater", exact = TRUE)
pr$estimateMean
9.75 pr$method[1] "One-Sample Permutation Test\n (Exact)"pr$sample.sizen
8 pr$p.value[1] 0.8515625p.value > \(\alpha = 0.05\). Brak podstaw do odrzucenia \(H_0\).
plot(pr,
main = "Test permutacyjny dla próby oparty na różnicy średnich",
xlab = "Różnica średnich",
ylab="Częstość")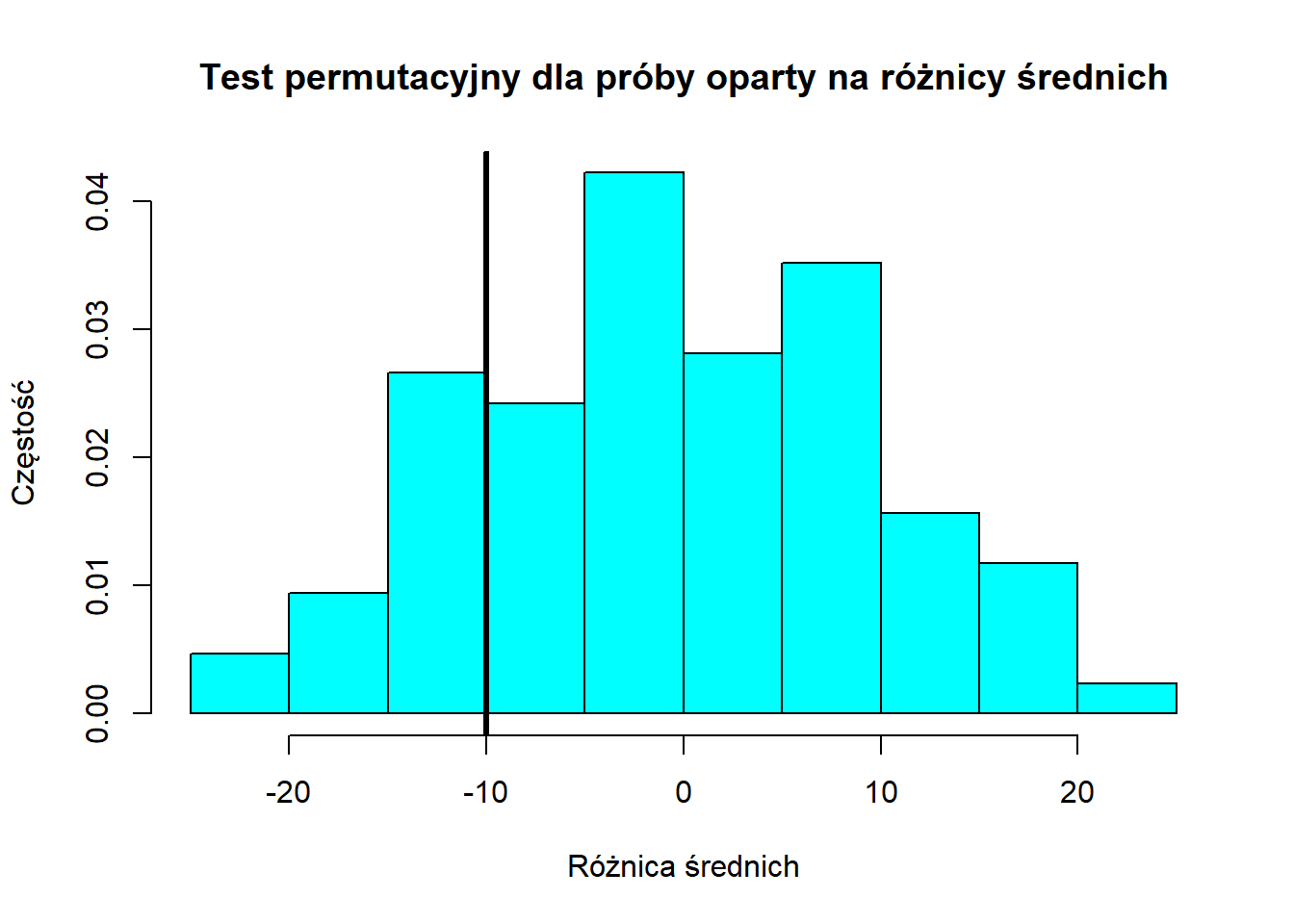
Test niezależności.
Test permutacyjny z wykorzystaniem przybliżenia asymptotycznego
#install.packages("perm")
library(perm)
permTS(CO2$uptake ~ CO2$Treatment ,
alternative = "less",
method = "pclt")
Permutation Test using Asymptotic Approximation
data: CO2$uptake by CO2$Treatment
Z = 2.9067, p-value = 0.9982
alternative hypothesis: true mean CO2$Treatment=nonchilled - mean CO2$Treatment=chilled is less than 0
sample estimates:
mean CO2$Treatment=nonchilled - mean CO2$Treatment=chilled
6.859524 p.value > \(\alpha = 0.05\). Brak podstaw do odrzucenia \(H_0\).
Asymptotyczny test permutacyjny dla K prób
#install.packages("perm")
library(perm)
permKS(CO2$uptake ~ CO2$Treatment ,
alternative = "less",
method = "pclt")
K-Sample Asymptotic Permutation Test
data: CO2$uptake by CO2$Treatment
Chi Square = 8.4489, df = 1, p-value = 0.003653p.value < \(\alpha =0.05\). Należy odrzucić \(H_0\) na rzecz \(H_1\).
\(H_0: m_1=m_2\)
\(H_1: m_1 > m_2\)
x1 = c(5, 6, 11, 14, 1, 2, 3)
x2 = c(7, 10, 15, 13, 12, 8, 9, 4)
x<-c(x1,x2)
T<-c()
n1 = length(x1)
n2 = length(x2)
n = n1 + n2
T0 = mean(x1)-mean(x2)
śr_x = mean(x)
N = 1000000
for (i in 1:N){
śr_x1 = mean(sample(x, n1))
śr_x2 = (śr_x*n - śr_x1*n1)/n2
T[i]=śr_x1-śr_x2
}
hist(T)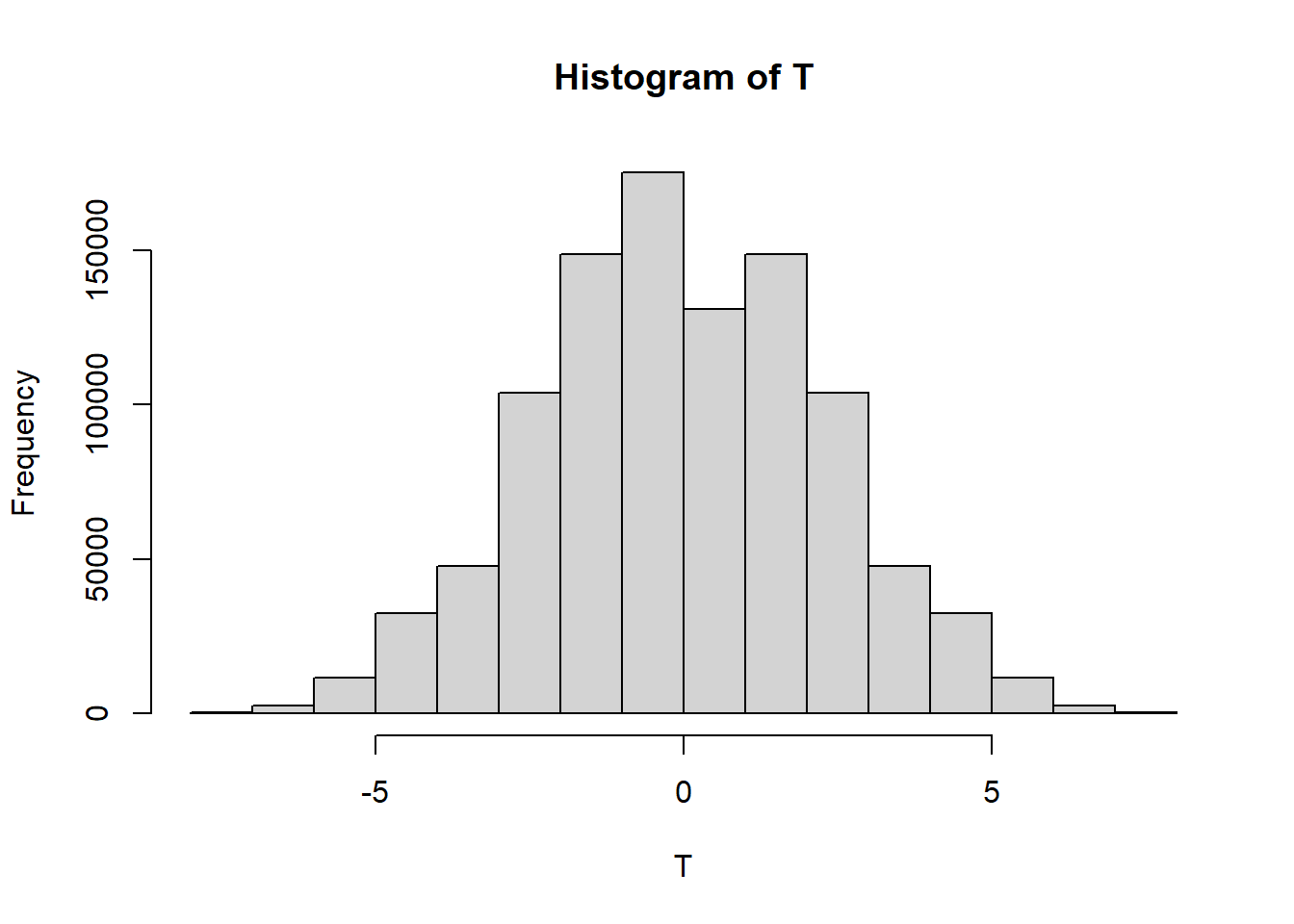
plot(table(T),type='h')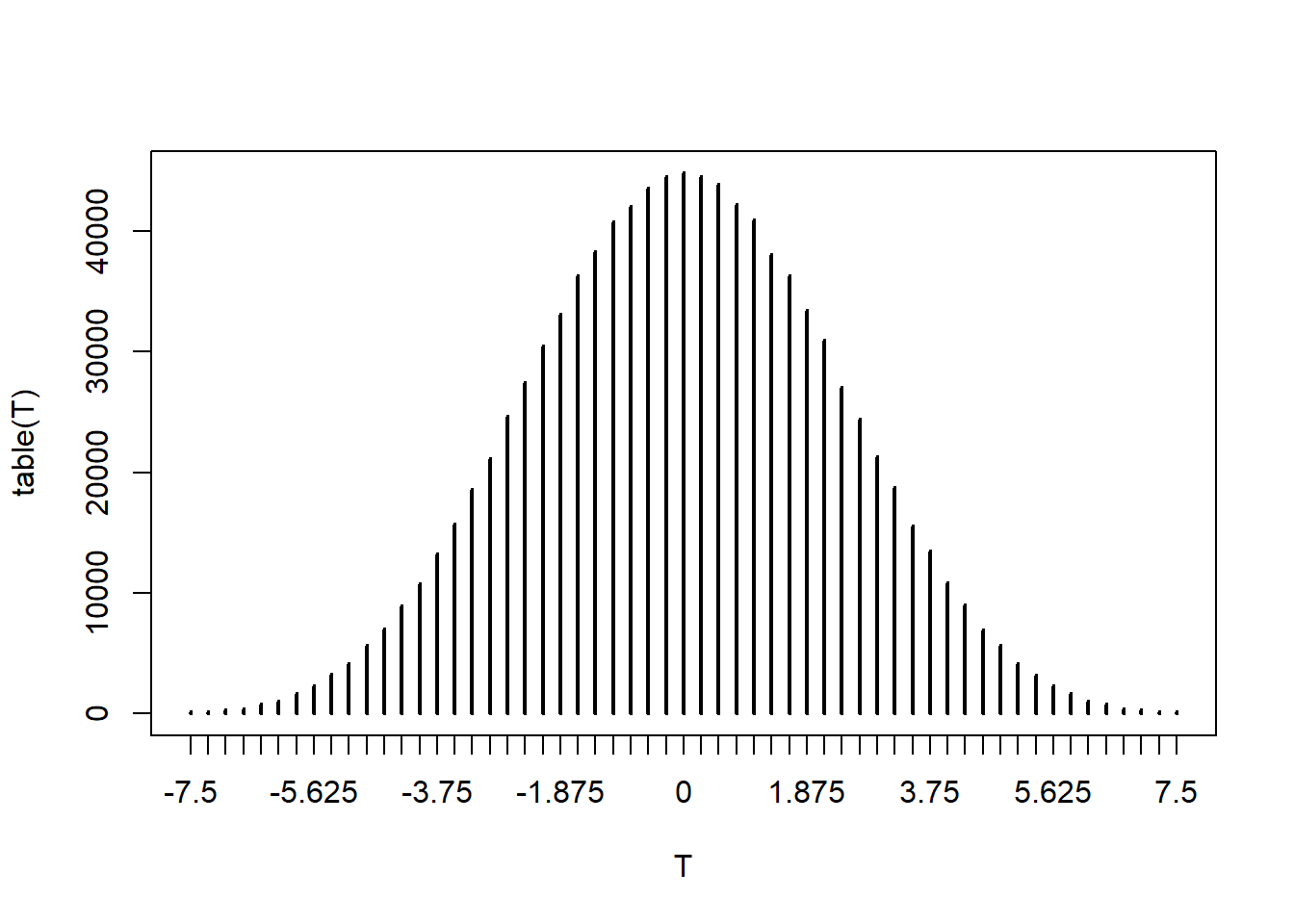
p=sum(T>=T0)/N
p[1] 0.953037p.value > \(\alpha = 0.05\). Brak podstaw do odrzucenia \(H_0\).
# dzielenie okna graficznego na 3 wiersze i 1 kolumnę
par(mfrow=c(3,1))
# generowanie liczb ze zbioru normalnego
x1 = rnorm(10, 29, 3.2) #liczba obserwacji, średnia, odchylenie standardowe
x2 = rnorm(13, 34, 1.25)
x = c(x1,x2)
# Określenie pierwszej, drugiej i trzeciej statystyki
T01=mean(x1) - mean(x2)
T02=mean(x1)
T03=mean(x1)/mean(x2)
T1=c(); T2=c(); T3=c()
N = 50000 # liczba powtórzeń pętli
for (i in 1:N){
samp_x = sample(x) #mieszanie danych
# Obliczanie statystyk dla każdej permutacji. Pierwsze 12 elementów po losowym wymieszaniu trafia do grupy "1". Pozostałe do grupy "2".
T1[i]= mean(samp_x[1:10])- mean(samp_x[11:23])
T2[i]= mean(samp_x[1:10])
T3[i]= mean(samp_x[1:10])/mean(samp_x[11:23])
}
# Standaryzacja statystyk
T1st = (T1-mean(T1))/sd(T1)
T2st = (T2-mean(T2))/sd(T2)
T3st = (T3-mean(T3))/sd(T3)
# Obliczanie p-value + tworzenie histogramu
sum(T1 >= T01) / N[1] 1hist(T1st, breaks = 10)
sum(T2 >= T02) / N[1] 1hist(T2st, breaks = 10)
sum(T3 >= T03) / N[1] 1hist(T3st, breaks = 10)
Niezależności ze statystyką chi-kwadrat
\(H_0\) : Badane zmienne są niezależne
\(H_1\): Badane zmienne są zależne
set.seed(150)
T = c()
N = 500
M = matrix (c(4, 4, 9, 8, 3, 2, 3, 5),3,3,byrow=TRUE)
chisq.test(M,correct = FALSE)$expected [,1] [,2] [,3]
[1,] 6.071429 4.857143 6.071429
[2,] 4.642857 3.714286 4.642857
[3,] 4.285714 3.428571 4.285714#Liczby oczekiwane są mniejsze od 5, nie można stosować testu chi^2
X = c(rep(1,M[1,1] + M[1,2] + M[1,3]),
rep(2,M[2,1] + M[2,2] + M[2,3]),
rep(3,M[3,1] + M[3,2] + M[3,3]))
Y=c(rep(1,M[1,1]),rep(2,M[1,2]),rep(3,M[1,3]),
rep(1,M[2,1]),rep(2,M[2,2]),rep(3,M[2,3]),
rep(1,M[3,1]),rep(2,M[3,2]),rep(3,M[3,3]))
t = table(X,Y)
t Y
X 1 2 3
1 4 4 9
2 8 3 2
3 3 5 4T0 = chisq.test(t,correct = FALSE)$statistic[[1]]
T0[1] 7.464819for (i in 1:1000){
danep = table(X,sample(Y))
T = c(T,chisq.test(danep, correct = FALSE)$statistic[[1]])
}
wynik = sum(T >= T0)/1000
wynik[1] 0.128wynik > \(\alpha = 0.05\). Brak podstaw do odrzucenia \(H_0\).
Współczynnika korelacji
set.seed(150)
X = rnorm(11, 15, 3)
Y = rnorm(11, 12, 2) + 0.5 * x1
XY = c(X, Y)
# obliczanie rzeczywistego współczynnika korelacji dla wygenerowanych X i Y
rho0 = cor(X, Y)
r = 0 # oblicza ile razy wylosowana korelacja okaże się równa lub większa od rh0
for (i in 1:1000){
Yp = sample(Y) # permutacja Y
# obliczanie korelacji między X, a nowo wylosowanym Yp. Korelacja większa lub równa rh0 zwiększa r o 1.
if (cor(X, Yp) >= rho0) r = r + 1
}
p_value = r/1000
p_value[1] 0.128p.value > \(\alpha=0.05\). Brak podstaw do odrzucenia \(H_0\).
An Introduction to the Bootstrap By Bradley Efron, R.J. Tibshirani, str. 202-204
Permutation Tests: A Practical Guide to Resampling Methods for Testing Hypotheses, Phillip Good
https://www.jwilber.me/permutationtest/
https://stat.ue.katowice.pl/testy_permutacyjne/index.html - Rozdziały 2-5