| Metoda | Autor | Idea |
|---|---|---|
| Bootstrap | B. Efron (1979) | losowanie ze zwracaniem, N ≥ 1000 razy |
| Jackknife | M. Quenouille (1949) | usuwanie kolejno jednej obserwacji |
| DRG | Hansen, Hurwitz, Madow | losowy podział próby na G grup |
| IRG | P.C. Mahalanobis | G niezależnych losowań z populacji |
| Zrównoważone półpróby | Wolter (1985) | systematyczny podział na pary półprób |
Metody repróbkowania
Bootstrap, Jackknife, DRG, IRG oraz metoda zrównoważonych półprób losowych
1. Wstęp
1.1 Wprowadzenie
Współczesna analityka danych coraz częściej zmaga się z sytuacjami, w których klasyczne metody statystyczne okazują się niewystarczające — dane są nieliczne, rozkład populacji nieznany, a estymatory zbyt złożone, by analitycznie ocenić ich precyzję. Odpowiedzią na te wyzwania są metody repróbkowania, które rewolucjonizują sposób myślenia o ocenie dokładności estymacji.
1.2 Metody nieparametryczne i repróbkowanie
W wielu praktycznych sytuacjach nie możemy założyć konkretnego rozkładu populacji lub postać estymatora jest zbyt złożona, by analitycznie wyznaczyć jego wariancję. W takich przypadkach sięgamy po metody nieparametryczne.
W przeciwieństwie do metod klasycznych:
- nie wymagają znajomości rozkładu zmiennej \(X\) w populacji
- opierają się bezpośrednio na danych empirycznych
- pozwalają ocenić precyzję estymatora “z samych danych”
Szczególną klasą metod nieparametrycznych są metody repróbkowania — zwane też metodami komputerowo intensywnymi.
1.3 Filozofia repróbkowania
Istotą tych metod jest wielokrotne wykorzystanie informacji zawartej w pojedynczej próbie \(S\) o liczebności \(n\).
Zamiast zakładać teoretyczny rozkład populacji, konstruujemy empiryczny rozkład estymatora poprzez:
- Generowanie wielu podprób z posiadanych danych
- Obliczanie wartości statystyki \(\hat{\theta}\) dla każdej podpróby
- Analizę rozrzutu tych wartości w celu oszacowania błędu
Zasada przewodnia: traktujemy próbę tak, jakby była ona całą populacją — niech dane mówią same za siebie.
1.4 Zastosowania
Metody repróbkowania stosujemy przede wszystkim do:
- aproksymacji rozkładu estymatorów i statystyk testowych
- szacowania wariancji złożonych estymatorów (kwantyle, współczynnik korelacji)
- konstrukcji przedziałów ufności bez założeń o normalności rozkładu
- oceny obciążenia estymatorów
- walidacji jakości badań ankietowych i sondażowych
1.5 Zalety i wady
Zalety
- Działają dla dowolnych statystyk, nawet bez wzoru na wariancję
- Brak założeń o rozkładzie populacji
- Proste w implementacji (np. w R)
- Odporne na asymetrię i wartości odstające
Wady
- Kosztowne obliczeniowo — bootstrap wymaga \(N \geq 1000\) powtórzeń
- Nie naprawią złej próby — błąd systematyczny zostanie powielony
- Nie tworzą nowych informacji — jedynie wydobywają te z danych
- Wyniki zależą od losowości — konieczne
set.seed()
1.6 Omawiane metody
2. Bootstrap
2.1 Definicja i historia
Metoda bootstrap została zaproponowana przez Bradleya Efrona w 1979 roku jako alternatywa dla metody jackknife. Nazwa pochodzi od angielskiego wyrażenia “to pull oneself up by one’s bootstraps” — podciągać się za własne sznurowadła — co dobrze oddaje ideę wnioskowania statystycznego “z samych danych”, bez odwoływania się do zewnętrznych założeń.
Bootstrap jest metodą komputerowo intensywną: zamiast rozwiązań analitycznych, wielokrotnie losuje próby z danych i na ich podstawie aproksymuje rozkład estymatora.
2.2 Ograniczenia i założenia metody bootstrap
Bootstrap może dawać słabe wyniki dla:
- bardzo małych prób,
- rozkładów o ciężkich ogonach,
- statystyk nieliniowych o niestabilnym rozkładzie,
- danych zależnych (np. szeregi czasowe bez modyfikacji bootstrapu)
Uwaga dotycząca założeń
Klasyczny bootstrap zakłada, że obserwacje są: - niezależne, - identycznie rozłożone (i.i.d.), - reprezentatywne dla populacji.
W przeciwnym razie konieczne są modyfikacje (np. block bootstrap).
2.3 Algorytm
Mając próbę \(S = \{x_1, x_2, \ldots, x_n\}\), postępujemy następująco:
- Traktujemy próbę \(S\) jako empiryczny rozkład populacji
- Losujemy \(N\) prób bootstrapowych \(S_1^*, S_2^*, \ldots, S_N^*\),
każda o liczebności \(n\), ze zwracaniem z próby \(S\) - Dla każdej próby bootstrapowej obliczamy wartość estymatora:
\(\hat{\theta}_i^* = T(S_i^*)\), \(\quad i = 1, 2, \ldots, N\) - Zbiór wartości \(\{\hat{\theta}_1^*, \ldots, \hat{\theta}_N^*\}\) tworzy empiryczny rozkład bootstrapowy estymatora \(\hat{\theta}\)
Zalecana liczba powtórzeń: \(N \geq 1000\), typowo \(N = 10\,000\).
2.4 Estymator bootstrapowy
Kluczowym wynikiem procedury bootstrapowej nie jest pojedyncza liczba, lecz empiryczny rozkład bootstrapowy statystyki:
\[ \left\{\hat{\theta}_1^*, \hat{\theta}_2^*, \ldots, \hat{\theta}_N^*\right\} \]
Rozkład ten aproksymuje rzeczywisty rozkład próbkowy statystyki \(\hat{\theta}\) i stanowi podstawę do:
Estymacji błędu standardowego
jako odchylenie standardowe wartości bootstrapowych:
\[ \widehat{SE}(\hat{\theta}) = \sqrt{\frac{1}{N-1} \sum_{i=1}^{N} \left(\hat{\theta}_i^* - \bar{\theta}^*\right)^2} \]
gdzie \(\bar{\theta}^*\) oznacza średnią wartości bootstrapowych.
Estymacji punktowej
jako średnia wartości bootstrapowych (jedna z możliwych definicji, niejedyna):
\[ \bar{\theta}^* = \frac{1}{N} \sum_{i=1}^{N} \hat{\theta}_i^* \]
Estymacji przedziałowej (metoda percentylowa)
Przedział ufności na poziomie \(1-\alpha\) wyznacza się jako kwantyle empirycznego rozkładu bootstrapowego (tj. rozkładu \(\{\hat{\theta}_i^*\}\)):
\[ \left[\hat{\theta}^*_{\alpha/2},\; \hat{\theta}^*_{1-\alpha/2}\right] \]
gdzie \(\hat{\theta}^*_{\alpha/2}\) i \(\hat{\theta}^*_{1-\alpha/2}\) to odpowiednio empiryczne kwantyle rzędu \(\alpha/2\) i \(1-\alpha/2\) z rozkładu bootstrapowego.
Estymacja obciążenia (bias)
Bootstrap pozwala oszacować obciążenie estymatora:
\[ \widehat{Bias}(\hat{\theta}) = \bar{\theta}^* - \hat{\theta} \]
gdzie: - \(\bar{\theta}^*\) — średnia z wartości bootstrapowych - \(\hat{\theta}\) — estymator z oryginalnej próby
Bootstrap nie generuje nowych informacji — jedynie aproksymuje rozkład estymatora na podstawie dostępnej próby.
2.5 Wariancja bootstrapowa
Wariancję estymatora \(\hat{\theta}\) szacujemy jako wariancję empiryczną wartości bootstrapowych:
\[ \widehat{D^2}(\hat{\theta}) = \frac{1}{N-1} \sum_{i=1}^{N} \left(\hat{\theta}_i^* - \bar{\theta}^*\right)^2 \]
Zauważmy, że zachodzi związek:
\[ \widehat{SE}(\hat{\theta}) = \sqrt{\widehat{D^2}(\hat{\theta})} \]
Bootstrapowy estymator wariancji jest wyznaczany czysto empirycznie — nie wymaga znajomości rozkładu populacji ani analitycznej postaci wariancji estymatora (która dla złożonych statystyk, np. mediany czy współczynnika korelacji, może być trudna do wyprowadzenia).
2.5 Przedziały ufności
Przedziały ufności — metoda normalna (oparta na CLT)
Alternatywnie, jeśli rozkład estymatora \(\hat{\theta}\) jest w przybliżeniu normalny (asymptotycznie zgodnie z Centralnym Twierdzeniem Granicznym), przedział ufności można wyznaczyć w oparciu o przybliżenie normalne oraz bootstrapową estymację błędu standardowego:
\[ \left[\hat{\theta} - z_{1-\alpha/2} \cdot \widehat{SE}(\hat{\theta}),\; \hat{\theta} + z_{1-\alpha/2} \cdot \widehat{SE}(\hat{\theta})\right] \]
gdzie:
- \(\hat{\theta}\) — estymator na oryginalnej próbie
- \(\widehat{SE}(\hat{\theta})\) — bootstrapowe odchylenie standardowe
- \(z_{1-\alpha/2} = \Phi^{-1}(1 - \alpha/2)\) — kwantyl rozkładu normalnego standardowego
Dla \(\alpha = 0{,}05\):
\[ z_{0{,}975} \approx 1{,}96 \]
Uwaga: metoda ta zakłada asymptotyczną normalność rozkładu estymatora i może być zawodna dla silnie skośnych lub asymetrycznych rozkładów.
Porównanie metod wyznaczania przedziałów ufności:
| Cecha | Metoda percentylowa | Metoda normalna (CLT) |
|---|---|---|
| Założenia o rozkładzie | brak | asymptotyczna normalność |
| Symetria przedziału | nie wymaga | symetryczny |
| Podstawa wyznaczania | kwantyle rozkładu bootstrapowego | estymator z oryginalnej próby ± błąd |
| Odporność na asymetrię | tak | nie |
| Zastosowanie | ogólne | proste estymatory (np. średnia) |
2.6 Przykład w R
Code
# Zbiór danych: airquality — prędkość wiatru (mph)
x <- na.omit(airquality$Wind)
n <- length(x)
N <- 10000
set.seed(123)
# Estymator na oryginalnej próbie
xsr <- mean(x)
# Rozkład bootstrapowy
z <- numeric(N)
for (i in 1:N) {
x_boot <- sample(x, n, replace = TRUE)
z[i] <- mean(x_boot)
}
# Wariancja i SE bootstrapowe
var1 <- var(z)
var2 <- sum((z - xsr)^2) / (N - 1)
print("Odchylenia standardowe — oceny:")[1] "Odchylenia standardowe — oceny:"Code
sqrt(var1)[1] 0.2841319Code
sqrt(var2)[1] 0.2841368Code
# Przedział ufności — metoda percentylowa
print("Przedział ufności (metoda percentylowa):")[1] "Przedział ufności (metoda percentylowa):"Code
quantile(z, c(0.025, 0.975)) 2.5% 97.5%
9.410458 10.522239 Code
# Przedział ufności — metoda normalna (CLT)
alfa <- 0.05
z_alfa <- qnorm(1 - alfa / 2)
print("Przedział ufności (metoda normalna):")[1] "Przedział ufności (metoda normalna):"Code
c(xsr - z_alfa * sqrt(var1),
xsr + z_alfa * sqrt(var1))[1] 9.400628 10.514405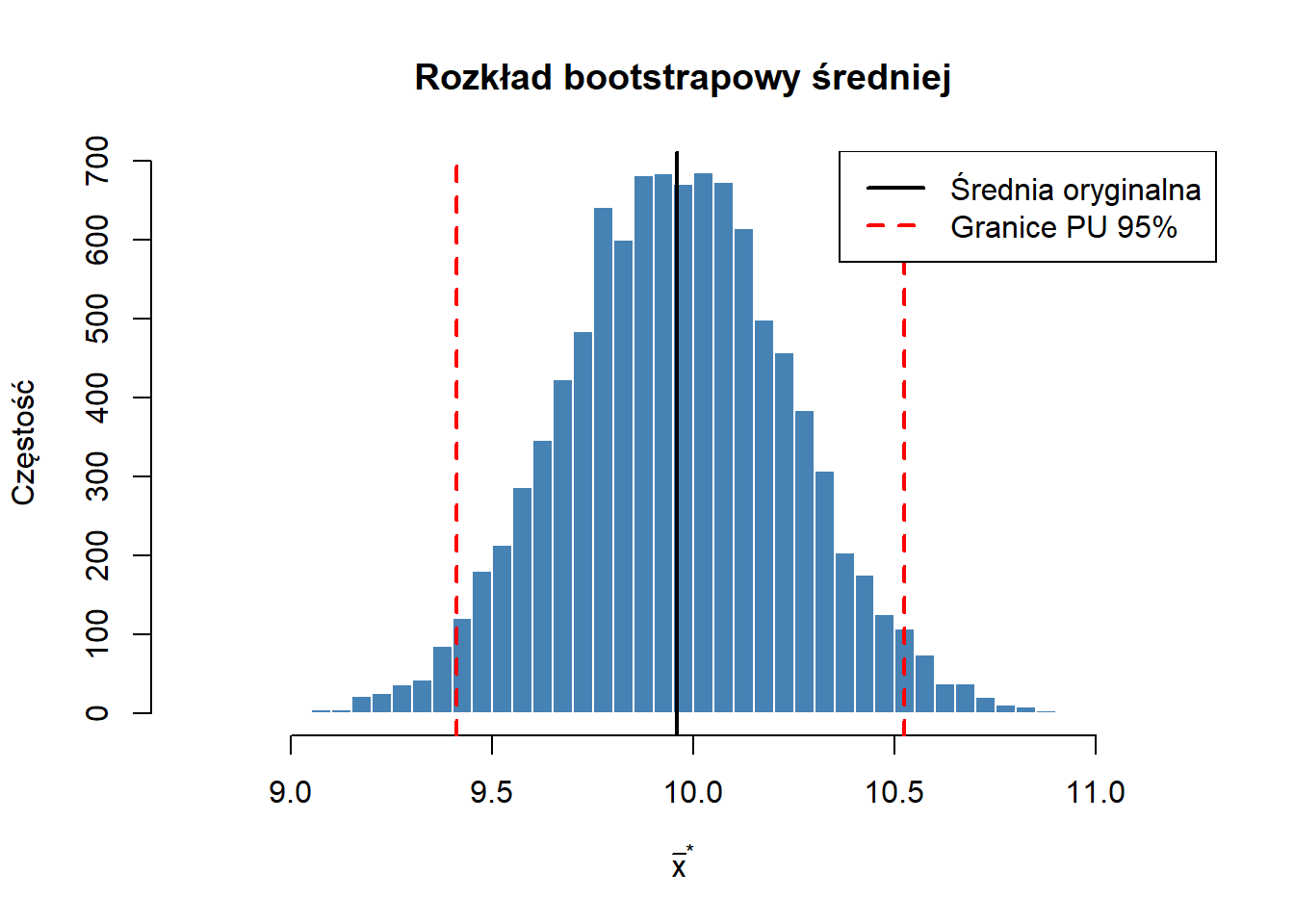
Code
# Bootstrap dla mediany — zbiór airquality, prędkość wiatru
x <- na.omit(airquality$Wind)
n <- length(x)
N <- 10000
set.seed(123)
# Estymator na oryginalnej próbie
med <- median(x)
# Rozkład bootstrapowy mediany
z_med <- numeric(N)
for (i in 1:N) {
x_boot <- sample(x, n, replace = TRUE)
z_med[i] <- median(x_boot)
}
# SE bootstrapowe
se_boot <- sqrt(var(z_med))
print("Mediana na oryginalnej próbie:")[1] "Mediana na oryginalnej próbie:"Code
med[1] 9.7Code
print("Bootstrapowe SE mediany:")[1] "Bootstrapowe SE mediany:"Code
se_boot[1] 0.3660278Code
# Przedział ufności — metoda percentylowa
print("Przedział ufności mediany (metoda percentylowa):")[1] "Przedział ufności mediany (metoda percentylowa):"Code
quantile(z_med, c(0.025, 0.975)) 2.5% 97.5%
9.2 10.3 Code
# Przedział ufności — metoda normalna (CLT)
alfa <- 0.05
z_alfa <- qnorm(1 - alfa / 2)
print("Przedział ufności mediany (metoda normalna):")[1] "Przedział ufności mediany (metoda normalna):"Code
c(med - z_alfa * se_boot,
med + z_alfa * se_boot)[1] 8.982599 10.417401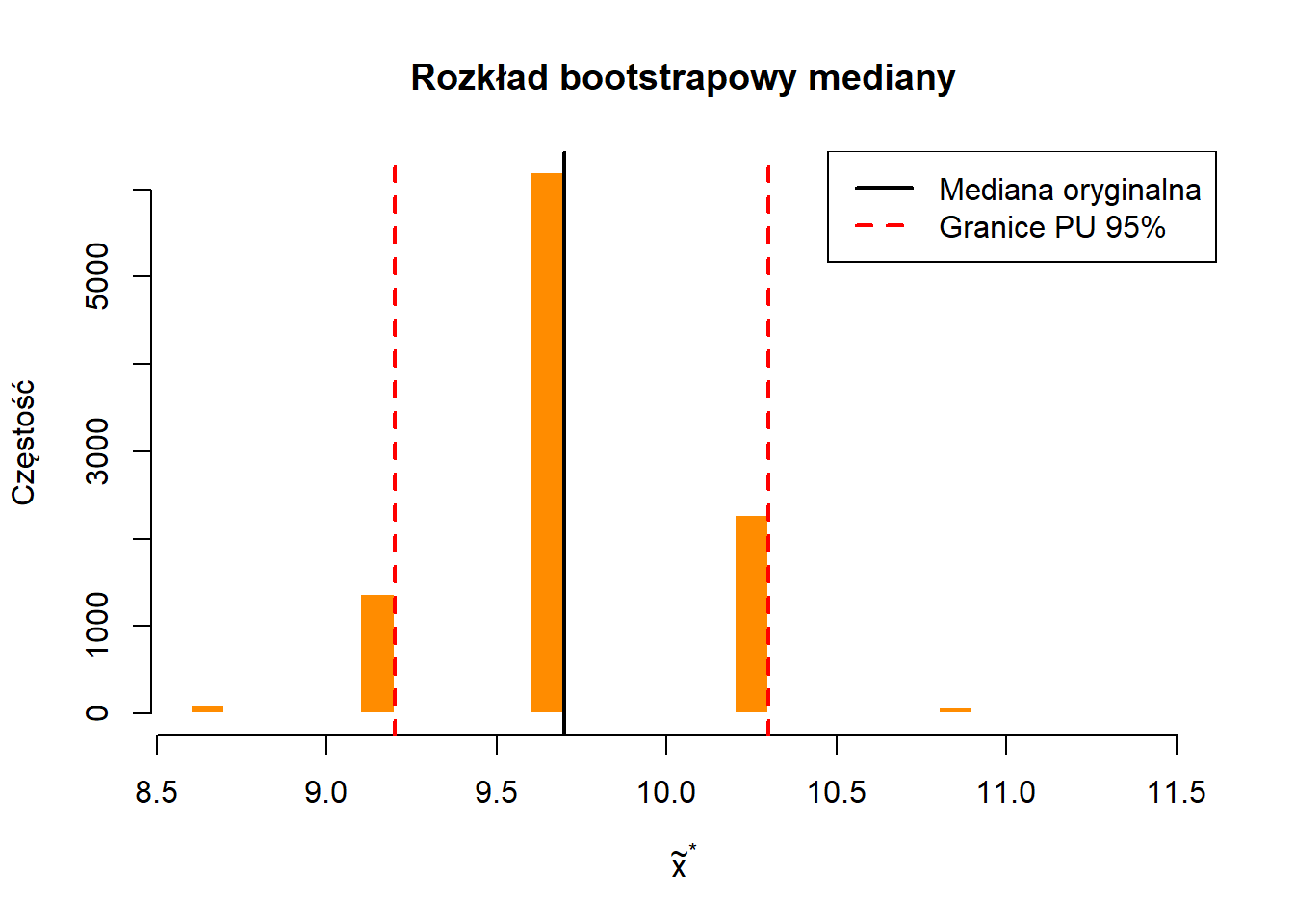
3. Jackknife
3.1 Definicja i historia
Metoda jackknife została zaproponowana przez Maurice’a Quenouille’a w 1949 roku jako technika redukcji obciążenia estymatora, a następnie rozwinięta przez Johna Tukeya w 1958 roku, który wprowadził pojęcie pseudowartości oraz zastosował metodę do estymacji błędów standardowych.
Nazwa pochodzi od scyzoryka — narzędzia wielofunkcyjnego — co dobrze oddaje wszechstronność metody. Jackknife jest metodą deterministyczną: w odróżnieniu od bootstrapu nie losuje prób, lecz systematycznie usuwa kolejne obserwacje z próby.
3.2 Ograniczenia i założenia metody jackknife
Jackknife może dawać słabe wyniki dla:
- statystyk niestabilnych — np. mediana (szczególnie przy małych próbach),
- bardzo małych prób — metoda traci dokładność asymptotyczną,
- danych zależnych — wymaga modyfikacji (np. jackknife blokowy),
- statystyk silnie nieliniowych — może niedoszacowywać wariancji.
Uwaga dotycząca założeń
Klasyczna wersja jackknife zakłada, że obserwacje są:
- niezależne,
- identycznie rozłożone (i.i.d.),
- reprezentatywne dla populacji.
W przypadku danych zależnych konieczne są modyfikacje metody.
3.3 Algorytm
Mając próbę \(S = \{x_1, x_2, \ldots, x_n\}\):
- Tworzymy \(n\) prób jackknife \(S_{(i)}\) poprzez usunięcie i-tej obserwacji: \[ S_{(i)} = \{x_1, \ldots, x_{i-1}, x_{i+1}, \ldots, x_n\} \]
- Dla każdej próby liczymy estymator: \[ \hat{\theta}_{(i)} = T(S_{(i)}), \quad i = 1, \ldots, n \]
- Wyznaczamy pseudowartości: \[ \tilde{\theta}_i = n\hat{\theta} - (n-1)\hat{\theta}_{(i)} \] gdzie \(\hat{\theta} = T(S)\).
Jackknife generuje dokładnie \(n\) podprób i nie zawiera elementu losowości.
3.4 Estymator jackknife
Zbiór pseudowartości: \[ \{\tilde{\theta}_1, \tilde{\theta}_2, \ldots, \tilde{\theta}_n\} \]
Estymacja punktowa
Estymator jackknife:
\[ \hat{\theta}_J = \frac{1}{n} \sum_{i=1}^{n} \tilde{\theta}_i \]
Dla statystyk liniowych (np. średniej) zachodzi \(\hat{\theta}_J = \hat{\theta}\), natomiast dla statystyk nieliniowych metoda może redukować obciążenie.
Estymacja błędu standardowego
\[ \widehat{SE}_J(\hat{\theta}) = \sqrt{\frac{1}{n(n-1)} \sum_{i=1}^{n} (\tilde{\theta}_i - \hat{\theta}_J)^2} \]
Estymacja obciążenia (bias)
\[ \widehat{Bias}_J(\hat{\theta}) = (n-1)\left(\hat{\theta}_{(\cdot)} - \hat{\theta}\right) \]
gdzie:
\[ \hat{\theta}_{(\cdot)} = \frac{1}{n} \sum_{i=1}^{n} \hat{\theta}_{(i)} \]
czyli średnia estymatorów z prób jackknife.
Skorygowany estymator:
\[ \hat{\theta}_{J,\text{corr}} = \hat{\theta} - \widehat{Bias}_J(\hat{\theta}) \]
3.5 Wariancja jackknife
Wariancja estymatora:
\[ \widehat{D^2}_J(\hat{\theta}) = \frac{1}{n(n-1)} \sum_{i=1}^{n} (\tilde{\theta}_i - \hat{\theta}_J)^2 \]
oraz:
\[ \widehat{SE}_J(\hat{\theta}) = \sqrt{\widehat{D^2}_J(\hat{\theta})} \]
3.6 Przedziały ufności
Przedział ufności na poziomie \(1-\alpha\) konstruujemy w oparciu o przybliżenie normalne (lub w małych próbach — rozkład t-Studenta):
\[ \left[ \hat{\theta}_J - t_{n-1,\,1-\alpha/2}\cdot \widehat{SE}_J(\hat{\theta}), \hat{\theta}_J + t_{n-1,\,1-\alpha/2}\cdot \widehat{SE}_J(\hat{\theta}) \right] \]
gdzie \(t_{n-1,\,1-\alpha/2}\) to kwantyl rozkładu t-Studenta.
Uwaga: Jackknife nie umożliwia stosowania metody percentylowej, ponieważ liczba pseudowartości (\(n\)) nie pozwala na stabilną estymację rozkładu empirycznego statystyki.
3.7 Przykład w R
3.7 Przykład w R
Code
# Jackknife dla średniej — zbiór airquality, prędkość wiatru
x <- na.omit(airquality$Wind)
n <- length(x)
# Estymator na pełnej próbie
xsr <- mean(x)
# Pseudowartości
z <- numeric(n)
for (i in 1:n) {
z[i] <- n * xsr - (n - 1) * mean(x[-i])
}
# Estymator jackknife
theta_J <- mean(z)
# Wariancja i SE jackknife
var_J <- var(z) / n
se_J <- sqrt(var_J)
print("Średnia na pełnej próbie:")[1] "Średnia na pełnej próbie:"Code
xsr[1] 9.957516Code
print("Estymator jackknife:")[1] "Estymator jackknife:"Code
theta_J[1] 9.957516Code
print("Jackknife SE:")[1] "Jackknife SE:"Code
se_J[1] 0.2848178Code
# Przedział ufności jackknife (t-Studenta)
alfa <- 0.05
t_kr <- qt(1 - alfa / 2, df = n - 1)
print("Przedział ufności jackknife:")[1] "Przedział ufności jackknife:"Code
c(theta_J - t_kr * se_J,
theta_J + t_kr * se_J)[1] 9.394804 10.520229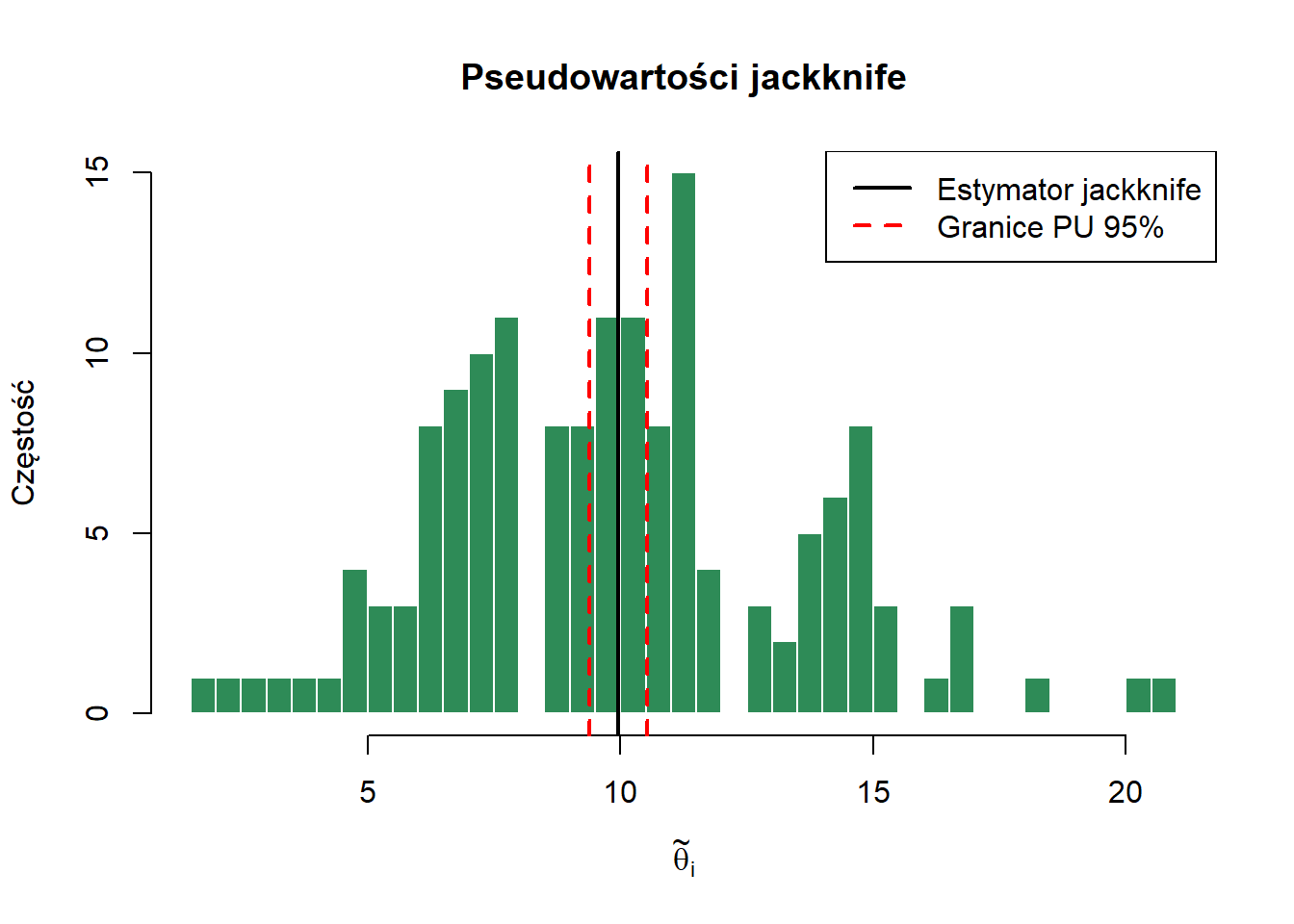
4. Metoda zależnych grup losowych (DRG)
4.1 Definicja i historia
Metoda zależnych grup losowych (ang. Dependent Random Groups, DRG) została zaproponowana przez M.H. Hansena, W.N. Hurwitza i W.G. Madowa w kontekście metod estymacji opartych na podziale próby.
W przeciwieństwie do bootstrapu i jackknife’a, DRG nie opiera się na wielokrotnym resamplingu danych. Zamiast tego wykorzystuje jednorazowy losowy podział dostępnej próby na grupy.
Grupy te są „zależne” w tym sensie, że wszystkie pochodzą z tej samej próby pierwotnej, a nie z niezależnych losowań z populacji.
4.2 Algorytm
Mając próbę \(S = \{x_1, x_2, \ldots, x_n\}\):
Losowo dzielimy próbę na \(G\) równolicznych grup, każda o liczebności \(m = n/G\): \[ S_1, S_2, \ldots, S_G \]
Dla każdej grupy obliczamy estymator: \[ \hat{\theta}_g = T(S_g), \quad g = 1, \ldots, G \]
Estymator DRG ma postać: \[ \hat{\theta}_{DRG} = \frac{1}{G} \sum_{g=1}^{G} \hat{\theta}_g \]
4.3 Interpretacja
DRG można interpretować jako: - przybliżenie zmienności estymatora w obrębie jednej próby - sposób „symulowania replik” poprzez podpróby - metodę redukcji wariancji opartą na agregacji grup
4.4 Estymacja wariancji
W DRG stosuje się dwa podejścia:
Wariant 1 (standardowy DRG)
\[ \hat{V}^{(1)}_{DRG} = \frac{1}{G(G-1)} \sum_{g=1}^{G} (\hat{\theta}_g - \hat{\theta}_{DRG})^2 \]
Wariant 2 (względem estymatora z całej próby)
\[ \hat{V}^{(2)}_{DRG} = \frac{1}{G(G-1)} \sum_{g=1}^{G} (\hat{\theta}_g - \hat{\theta})^2 \]
gdzie \(\hat{\theta}\) to estymator liczony na całej próbie.
Uwaga: wariant 2 ma charakter pomocniczy i nie zawsze jest stosowany w klasycznych definicjach DRG.
Błąd standardowy: \[ \widehat{SE}_{DRG} = \sqrt{\hat{V}_{DRG}} \]
4.5 Ograniczenia i założenia
Metoda DRG zakłada, że:
- obserwacje są niezależne i identycznie rozłożone (i.i.d.)
- próba jest reprezentatywna dla populacji
- losowy podział nie wprowadza systematycznego błędu
DRG może dawać słabe wyniki dla: - małych prób (małe \(m\) i \(G\)) - silnej heterogeniczności danych - danych zależnych (np. szeregi czasowe)
4.6 Przykład w R
Code
# DRG dla średniej — airquality$Wind jako populacja, losujemy próbę
set.seed(42)
populacja <- na.omit(airquality$Wind)
x <- sample(populacja, 70) # próba n = 70
n <- length(x)
G <- 7 # liczba grup
m <- n / G # liczebność grupy = 10
# Losowy podział próby na G grup
kolejnosc <- sample(1:n)
x_perm <- x[kolejnosc]
# Estymatory grupowe
theta_g <- numeric(G)
for (g in 1:G) {
idx <- ((g - 1) * m + 1):(g * m)
theta_g[g] <- mean(x_perm[idx])
}
# Estymator DRG
theta_DRG <- mean(theta_g)
# Estymator na całej próbie
theta_hat <- mean(x)
print("Estymatory grupowe:")[1] "Estymatory grupowe:"Code
theta_g[1] 11.12 9.74 11.40 12.15 10.77 10.72 9.50Code
print("Estymator DRG:")[1] "Estymator DRG:"Code
theta_DRG[1] 10.77143Code
print("Estymator na całej próbie:")[1] "Estymator na całej próbie:"Code
theta_hat[1] 10.77143Code
# Wariancja — wariant 1 (względem theta_DRG)
V1 <- sum((theta_g - theta_DRG)^2) / (G * (G - 1))
# Wariancja — wariant 2 (względem theta z całej próby)
V2 <- sum((theta_g - theta_hat)^2) / (G * (G - 1))
print("SE (wariant 1):")[1] "SE (wariant 1):"Code
sqrt(V1)[1] 0.348469Code
print("SE (wariant 2):")[1] "SE (wariant 2):"Code
sqrt(V2)[1] 0.348469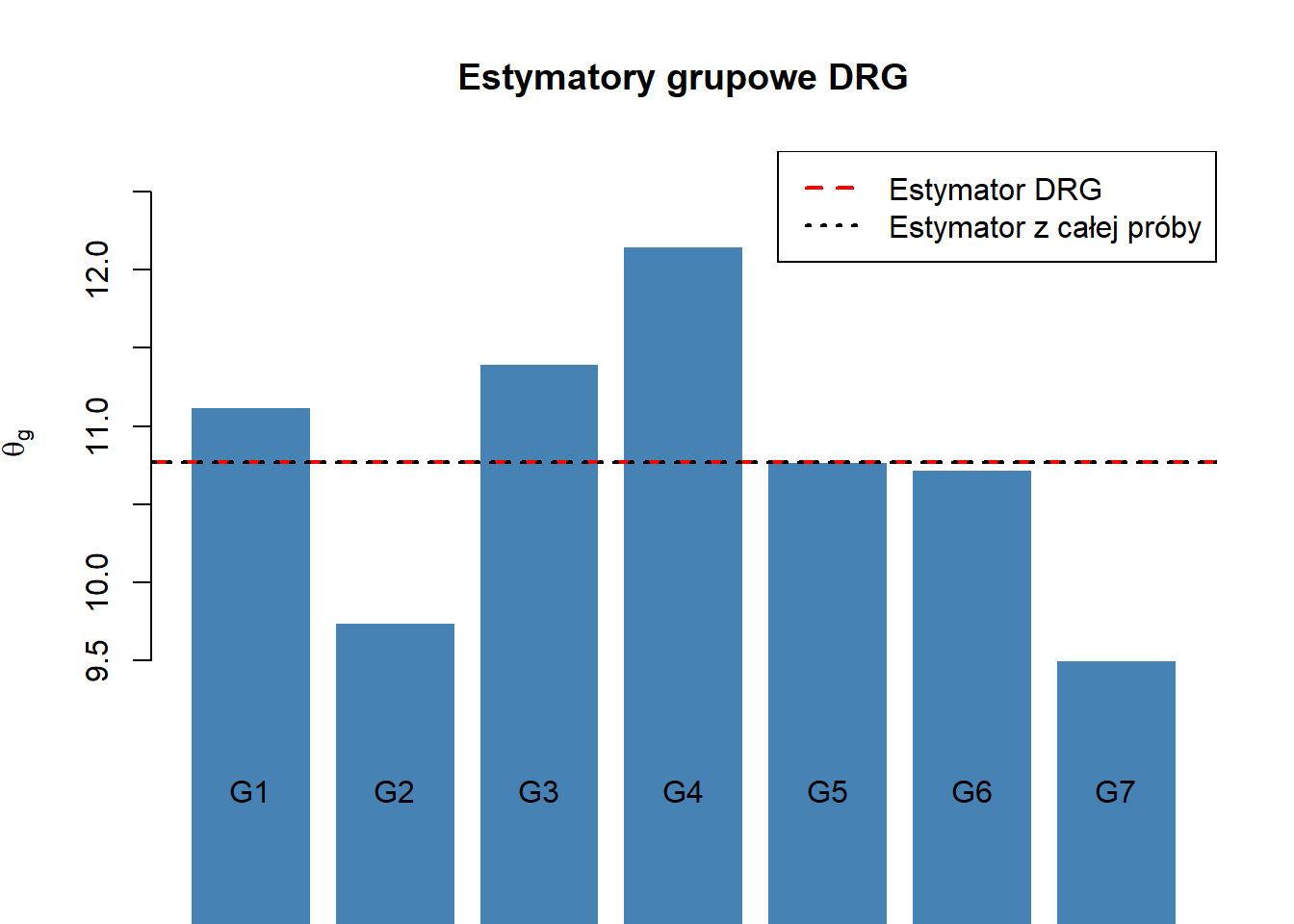
5. Metoda niezależnych grup losowych (IRG)
5.1 Definicja i historia
Metoda niezależnych grup losowych (ang. Independent Random Groups, IRG) została zaproponowana przez P.C. Mahalanobisa.
IRG nie wymaga wielokrotnego resamplingu jednej próby (jak bootstrap), ale opiera się na wielokrotnych niezależnych losowaniach z populacji lub jej empirycznej reprezentacji. W odróżnieniu od DRG, grupy tworzymy już na etapie pobierania próby.
5.2 Algorytm
Zamiast pobierać jedną dużą próbę i ją dzielić, postępujemy następująco:
- \(G\)-krotnie niezależnie losujemy próby po \(m = n/G\) elementów z całej populacji (każde losowanie niezależnie od pozostałych).
- Dla każdej grupy \(g\) obliczamy wartość estymatora: \[\hat{\theta}_g = T(S_g), \quad g = 1, 2, \ldots, G\]
- Estymator IRG parametru \(\theta\) to średnia estymatorów grupowych: \[\hat{\theta}_{IRG} = \frac{1}{G} \sum_{g=1}^{G} \hat{\theta}_g\]
Kluczowa różnica względem DRG: każda grupa pochodzi z osobnego, niezależnego aktu losowania — grupy są probabilistycznie niezależne, co jest fundamentalnym założeniem metody.
5.3 Estymacja wariancji
Analogicznie do DRG, dostępne są dwa warianty:
Wariant 1 — odwołuje się do \(\hat{\theta}_{IRG}\): \[\hat{V}^{(1)}_{IRG} = \frac{1}{G(G-1)} \sum_{g=1}^{G} \left(\hat{\theta}_g - \hat{\theta}_{IRG}\right)^2\]
Wariant 2 — odwołuje się do \(\hat{\theta}\) z połączonych prób: \[\hat{V}^{(2)}_{IRG} = \frac{1}{G(G-1)} \sum_{g=1}^{G} \left(\hat{\theta}_g - \hat{\theta}\right)^2\]
Błąd standardowy: \(\widehat{SE}_{IRG} = \sqrt{\hat{V}_{IRG}}\)
Uwaga interpretacyjna: estymator wariancji odnosi się do zmienności estymatorów grupowych \(\hat{\theta}_g\), nie do zmienności pojedynczych obserwacji.
5.4 DRG vs IRG — porównanie
| Cecha | DRG | IRG |
|---|---|---|
| Sposób tworzenia grup | Podział jednej próby | Osobne losowania z populacji |
| Zależność grup | Zależne | Niezależne |
| Etap losowania | Po pobraniu próby | Podczas pobierania próby |
| Założenie probabilistyczne | Zależność indukowana podziałem | Niezależne próby |
| Estymator | Średnia estymatorów grupowych | Średnia estymatorów grupowych |
| Formuły wariancji | Takie same | Takie same |
5.5 Przykład w R
Code
# IRG dla średniej — airquality$Wind jako populacja empiryczna
# Uwaga: stosujemy próbę empiryczną jako substytut pełnej populacji
# (IRG w wersji opartej na finite population surrogate)
set.seed(42)
populacja <- airquality$Wind
populacja <- populacja[!is.na(populacja)]
G <- 7 # liczba grup
m <- 10 # liczebność każdej grupy
# Sprawdzenie warunku minimalnej liczebności
stopifnot(length(populacja) >= m)
# G niezależnych losowań z populacji empirycznej
# Grupy są niezależne warunkowo na populacji źródłowej,
# ale mogą się częściowo nakładać — jest to akceptowalne
# w kontekście dydaktycznym
theta_g <- numeric(G)
grupy <- vector("list", G)
for (g in 1:G) {
grupy[[g]] <- sample(populacja, m, replace = FALSE)
theta_g[g] <- mean(grupy[[g]])
}
# Estymator IRG
theta_IRG <- mean(theta_g)
# Estymator na połączonych próbach
theta_hat <- mean(unlist(grupy))
print("Estymatory grupowe:")[1] "Estymatory grupowe:"Code
theta_g[1] 10.48 9.78 10.43 8.48 11.34 12.50 9.28Code
print("Estymator IRG:")[1] "Estymator IRG:"Code
theta_IRG[1] 10.32714Code
print("Estymator na połączonych próbach:")[1] "Estymator na połączonych próbach:"Code
theta_hat[1] 10.32714Code
# Wariancja estymatorów grupowych (zmienność między grupami)
V1 <- sum((theta_g - theta_IRG)^2) / (G * (G - 1))
V2 <- sum((theta_g - theta_hat)^2) / (G * (G - 1))
print("SE (wariant 1):")[1] "SE (wariant 1):"Code
sqrt(V1)[1] 0.5021132Code
print("SE (wariant 2):")[1] "SE (wariant 2):"Code
sqrt(V2)[1] 0.5021132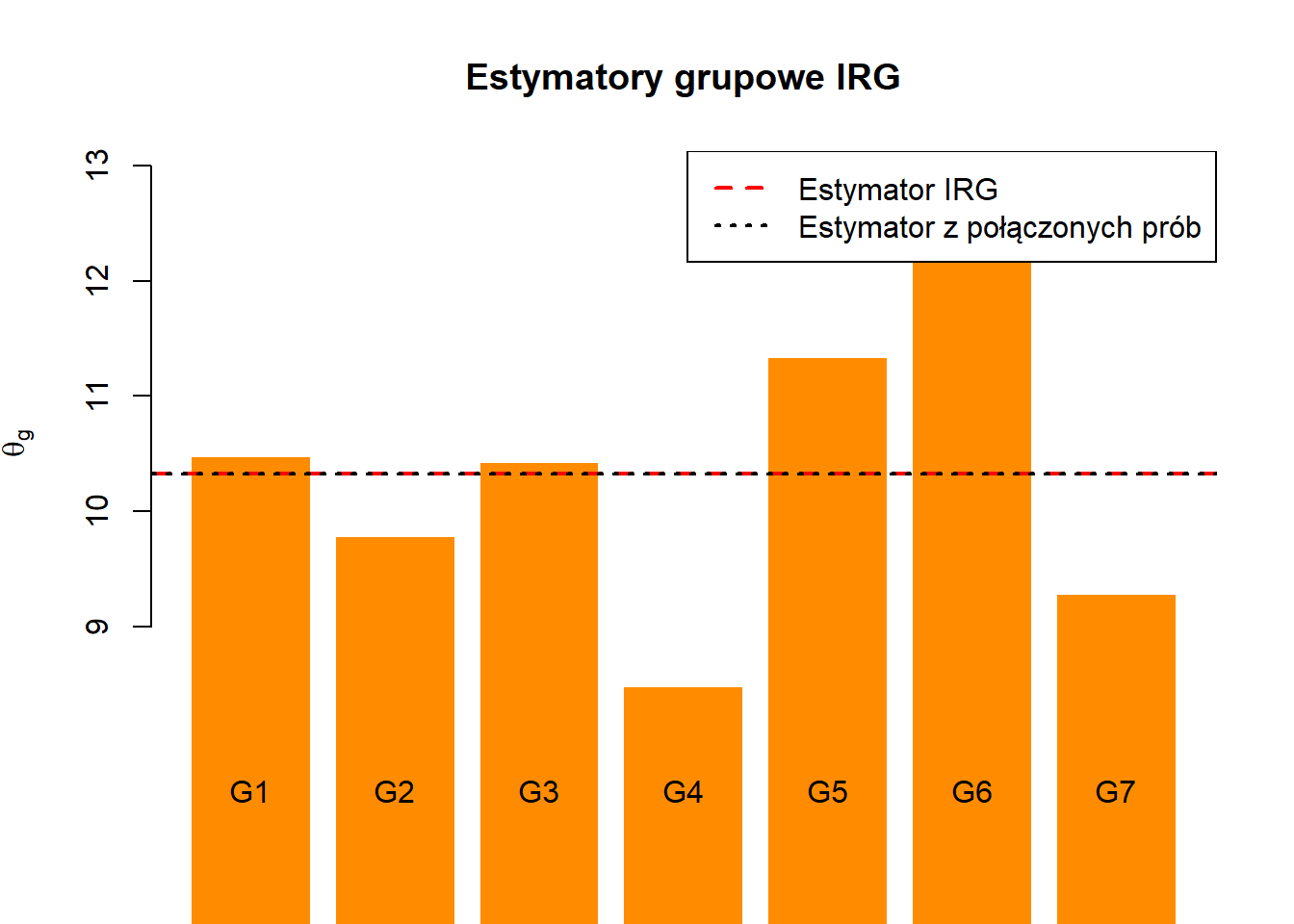
6. Metoda zrównoważonych półprób losowych (BRR)
6.1 Geneza i zastosowanie
Metoda zrównoważonych półprób losowych (Balanced Repeated Replication, BRR) została zaproponowana przez McCarthy’ego (1969) jako narzędzie do estymacji wariancji w złożonych schematach losowania, w szczególności w próbach warstwowych.
Metoda ta jest szczególnie użyteczna, gdy:
- populacja jest podzielona na \(L\) warstw,
- z każdej warstwy losowane są dokładnie \(n_h = 2\) jednostki (PSU — Primary Sampling Units).
6.2 Idea metody
Zamiast losować nowe próby z populacji, BRR tworzy serie replikacji poprzez systematyczny wybór jednej z dwóch jednostek w każdej warstwie.
W \(r\)-tej replikacji z każdej warstwy wybiera się jedną jednostkę, tworząc tzw. półpróbę (half-sample) zawierającą po jednej jednostce z każdej z \(L\) warstw.
Estymator wariancji oparty na \(R\) replikacjach ma postać:
\[ \widehat{V}_{BRR}(\hat{\theta}) = \frac{1}{R-1} \sum_{r=1}^{R} \left( \hat{\theta}^{(r)} - \hat{\theta} \right)^2 \]
gdzie \(\hat{\theta}^{(r)}\) oznacza estymator z \(r\)-tej replikacji, a \(\hat{\theta}\) estymator z pełnej próby.
6.3 Macierze Hadamarda — zrównoważenie replikacji
Kluczową cechą BRR jest zrównoważenie replikacji, osiągane dzięki macierzom Hadamarda — kwadratowym macierzom ortogonalnym o elementach \(\pm 1\), spełniających warunek:
\[ H H^{T} = R I \]
Dzięki nim:
- liczba replikacji jest redukowana do najmniejszej wielokrotności 4 większej lub równej \(L\),
- każda jednostka występuje w dokładnie połowie replikacji,
- replikacje są ortogonalne (niezależne w sensie konstrukcyjnym).
Przykład: dla \(L = 4\) wystarczą \(R = 4\) replikacje zamiast \(2^4 = 16\).
6.4 Wagi replikacyjne
Schemat BRR można wyrazić przez wagi replikacyjne \(w^{(r)}_{hi}\):
\[ w^{(r)}_{hi} = \begin{cases} 2 \cdot w_{hi} & \text{jeśli jednostka jest wybrana w replikacji } r \\ 0 & \text{w przeciwnym wypadku} \end{cases} \]
gdzie \(w_{hi}\) to oryginalna waga jednostki \(i\) z warstwy \(h\).
W praktyce stosuje się również modyfikację Fay’a, w której zamiast mnożnika 2 używa się wag stabilizujących, co poprawia stabilność estymacji.
6.5 Rozszerzenia BRR
Oryginalna metoda McCarthy’ego wymaga \(n_h = 2\) PSU na warstwę. Zaproponowano rozszerzenia dla \(n_h > 2\) (Gurney & Jewett 1975; Wu 1991; Sitter 1993), jednak ich stosowanie jest ograniczone ze względu na:
- złożoność kombinatoryczną (gwałtowny wzrost liczby replikacji),
- trudności w konstrukcji odpowiednich macierzy ortogonalnych.
6.6 Porównanie z innymi metodami
| Cecha | BRR | Jackknife | Bootstrap |
|---|---|---|---|
| Schemat losowania | n_h = 2 PSU/warstwę | dowolny | dowolny |
| Liczba replikacji | R ≈ L | zależne od liczby PSU | R ≈ 200–1000 |
| Zrównoważenie | dokładne | częściowe | asymptotyczne |
| Zgodność dla kwantyli | tak | nie (delete-1) | tak |
| Stabilność estymatora | wysoka | wysoka | umiarkowana |
7. Literatura
Wu, C. F. J. (1986). Jackknife, Bootstrap and Other Resampling Methods in Regression Analysis.
The Annals of Statistics, 14(4), 1261–1295.
DOI: 10.1214/aos/1176350142
*(wykorzystane w projekcie: s. 1261–1263 — motywacja i przegląd metod repróbkowania;- 1263–1266 — algorytm jackknife, pseudowartości i estymator wariancji (wzór 2.3);
- 1265–1266 — definicja bootstrapu (Efron 1979), bootstrapowy estymator wariancji i metoda percentylowa (wzór 2.10);
- 1279–1282 — własności wariancji bootstrapowej, obciążenie przy heteroskedastyczności;
- 1285–1287 — estymacja i redukcja obciążenia estymatora).*
- 1263–1266 — algorytm jackknife, pseudowartości i estymator wariancji (wzór 2.3);
Young, P. (2010). Jackknife and Bootstrap Resampling Methods in Statistical Analysis to Correct for Bias. University of California, Santa Cruz.
PDF: physicsfaculty.bnu.edu.cn
(s. 2–5: definicja i konstrukcja jackknife + estymacja błędu; s. 7–9: bootstrap (losowanie z zwracaniem), estymacja błędu, przykład z medianą i uwaga dlaczego jackknife bywa słaby dla mediany)Kolenikov, S. (2004). Applications of quasi-Monte Carlo methods in survey estimation (Project description, NSF-04-1269).
PDF: staskolenikov.net/talks/NSF-04-1269-Kolenikov-QMCBRR.pdf
*(s. 2: omówienie BRR dla \(n_h=2\) PSU/warstwę + rola macierzy Hadamarda i liczba replikacji;- 2–3: jackknife w badaniach złożonych + uwaga o niezgodności delete-1 dla kwantyli;
- 3: bootstrap dla prób złożonych (Rao & Wu) + idea wag replikacyjnych dla BRR/jackknife/bootstrap)*
- 2–3: jackknife w badaniach złożonych + uwaga o niezgodności delete-1 dla kwantyli;
Kisielińska, J. (2016). Rozkłady wybranych bootstrapowych estymatorów mediany oraz zastosowanie dokładnej metody percentyli do jej przedziałowego szacowania.
Przegląd Statystyczny, 63(4), 411–429. DOI: 10.5604/01.3001.0014.1223.
PDF: ps.stat.gov.pl/PS/2016/4/ps_4_2016__06_JOANNA%20KISIELI%C5%83SKA%20ROZK%C5%81ADY%20WYBRANYCH%20BOOTSTRAPOWYCH%20ESTYMATOR%C3%93W%20MEDIANY%20ORAZ%20ZASTOSOWANIE.pdf
*(wykorzystane w projekcie: s. 411–412 — idea bootstrapu i „dokładnej” metody bootstrapowej (exact bootstrap);- 412–413 — estymatory mediany i rozróżnienie przypadku (n) nieparzystego/parzystego;
- 414–418 — rozkłady bootstrapowych estymatorów mediany (własności i trudności dla (n) parzystego);
- 418–420 — metoda percentylowa / „dokładna metoda percentyli” i wyznaczanie granic PU dla rozkładu dyskretnego).*
- 412–413 — estymatory mediany i rozróżnienie przypadku (n) nieparzystego/parzystego;