Code
options(repos = c(CRAN = "https://cloud.r-project.org/"))
install.packages("tidyverse")
library(tidyverse)Test pustych cel oraz użycie AI w programowaniu w języku R
Celem niniejszego projektu jest przedstawienie zasad działania oraz przykładów zastosowania testu pustych cel David-Hellwiga. Warto na wstępie zaznaczyć, że stanowi on niezwykle interesujące narzędzie w grupie testów nieparametrycznych. Koncepcja ta została pierwotnie zaproponowana w latach 50. XX wieku przez angielską statystyczkę, Florence Nightingale David. Następnie polski ekonometryk, Zdzisław Hellwig, rozwinął tę metodę, proponując wykorzystanie liczby pustych cel jako statystyki testowej do weryfikacji złożonej hipotezy o normalności rozkładu.
Ponadto w celu przeprowadzenia testu pustych cel posłużę się sztuczną inteligencją, a konkretnie modelem Gemini 3.1 Pro.
options(repos = c(CRAN = "https://cloud.r-project.org/"))
install.packages("tidyverse")
library(tidyverse)Test pustych cel jest nieparametrycznym testem zgodności, którego głównym celem jest weryfikacja, czy analizowana próba badawcza pochodzi z populacji o z góry określonym rozkładzie teoretycznym. Najczęściej weryfikowaną hipotezą jest założenie o normalności rozkładu. W takim przypadku układ hipotez prezentuje się następująco:
\(H_0\): Analizowana próba pochodzi z populacji o rozkładzie normalnym.
\(H_1\): Analizowana próba nie pochodzi z populacji o rozkładzie normalnym.
Choć test ten najsilniej kojarzy się z weryfikacją rozkładu normalnego, jego konstrukcja pozwala na zastosowanie go do badania zgodności z dowolnym innym ciągłym rozkładem prawdopodobieństwa, takim jak na przykład rozkład jednostajny czy wykładniczy.
Jak sama nazwa wskazuje, do testu pustych cel niezbędne jest zdefiniowanie owych cel. Podstawowym warunkiem ich wyznaczenia jest to, aby prawdopodobieństwo trafienia pojedynczej obserwacji (wylosowanej z rozkładu określającego hipotezę zerową) do danej celi wynosiło \(1/m\), gdzie \(m\) to liczba podzbiorów (cel). Przykładowo, dla rozkładu jednostajnego można dokonać podziału na \(m\) cel za pomocą następującej prostej funkcji:
cele_unif=function(m){
cele=c(qunif(0))
for (i in 1:m) {
cele[i+1]=qunif(i/m)
}
cele
}Możemy teraz wywołać powyższą funkcję dla 5 i 10 cel.
cele_unif(5)[1] 0.0 0.2 0.4 0.6 0.8 1.0cele_unif(10) [1] 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0W przypadku rozkładu jednostajnego granice te są proste do określenia, jednak możemy wyznaczać takie przedziały również dla innych rozkładów. Poniżej przedstawiłem funkcję, która pozwoli wyznaczyć i porównać przedziały (cele) dla rozkładu jednostajnego, normalnego oraz wykładniczego.
cele=function(m){
cele_u=c(qunif(0))
cele_norm=c(qnorm(0))
cele_exp=c(qexp(0))
for (i in 1:m) {
cele_u[i+1]=qunif(i/m)
cele_norm[i+1]=qnorm(i/m)
cele_exp[i+1]=qexp(i/m)
}
wynik=list('cele w rozkładzie jednostajnym'=cele_u,'cele w rozkładzie normalnym'=cele_norm,'cele w rozkładzie wykładniczym'=cele_exp)
wynik
}Wywołamy tą funkcję ponownie dla 5 i 10 cel:
cele(5)$`cele w rozkładzie jednostajnym`
[1] 0.0 0.2 0.4 0.6 0.8 1.0
$`cele w rozkładzie normalnym`
[1] -Inf -0.8416212 -0.2533471 0.2533471 0.8416212 Inf
$`cele w rozkładzie wykładniczym`
[1] 0.0000000 0.2231436 0.5108256 0.9162907 1.6094379 Infcele(10)$`cele w rozkładzie jednostajnym`
[1] 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
$`cele w rozkładzie normalnym`
[1] -Inf -1.2815516 -0.8416212 -0.5244005 -0.2533471 0.0000000
[7] 0.2533471 0.5244005 0.8416212 1.2815516 Inf
$`cele w rozkładzie wykładniczym`
[1] 0.0000000 0.1053605 0.2231436 0.3566749 0.5108256 0.6931472 0.9162907
[8] 1.2039728 1.6094379 2.3025851 InfPodsumowując powyższe, nasze podzbiory, czyli cele w teście pustych cel, wyznacza się wykorzystując kwantyle rozkładu dla równych przedziałów prawdopodobieństwa.Podejście to jest uniwersalne i pozwala na przygotowanie podziału dla praktycznie dowolnego rozkładu ciągłego, co jest fundamentem całego testu.
Statystyką testową w teście Davida-Hellwiga jest liczba pustych cel, a sam test charakteryzuje się prawostronnym obszarem krytycznym. Jako że wzór na dokładny rozkład prawdopodobieństwa tej statystyki (przy założeniu prawdziwości hipotezy zerowej) jest złożony i żmudny w ręcznych obliczeniach, do wygenerowania odpowiedniego kodu posłużono się sztuczną inteligencją. Model poproszono o stworzenie narzędzia w języku R, wykorzystując do tego następujące zapytanie (prompt): “stwórz funkcję w R pozwalającą wyznaczyć dokładny rozkład prawdopodobieństwa statystyki testowej testu pustych cel przy założeniu że hipoteza zerowa jest prawdziwa”. Po kilku iteracjach i optymalizacjach kodu, ostateczna wersja funkcji prezentuje się następująco:
rozklad_davida_hellwiga <- function(n, m = n) {
wewnetrzne_p_k <- function(k) {
if (k < 0 || k >= m) return(0)
r <- 0:(m - k)
skladniki_sumy <- (-1)^r * choose(m - k, r) * (1 - (k + r) / m)^n
suma <- sum(skladniki_sumy)
return(choose(m, k) * suma)
}
mozliwe_k <- 0:(m - 1)
prawdopodobienstwa <- sapply(mozliwe_k, wewnetrzne_p_k)
tabela_rozkladu <- data.frame(
'Liczba_pustych_cel_k' = mozliwe_k,
'Prawdopodobienstwo' = prawdopodobienstwa
)
return(tabela_rozkladu)
}Wywołajmy ją, tak jak wcześniejsze funkcje, dla \(n=5\) oraz \(n=10\):
rozklad_davida_hellwiga(5) Liczba_pustych_cel_k Prawdopodobienstwo
1 0 0.0384
2 1 0.3840
3 2 0.4800
4 3 0.0960
5 4 0.0016rozklad_davida_hellwiga(10) Liczba_pustych_cel_k Prawdopodobienstwo
1 0 0.000362880
2 1 0.016329600
3 2 0.136080000
4 3 0.355622400
5 4 0.345144240
6 5 0.128595600
7 6 0.017188920
8 7 0.000671760
9 8 0.000004599
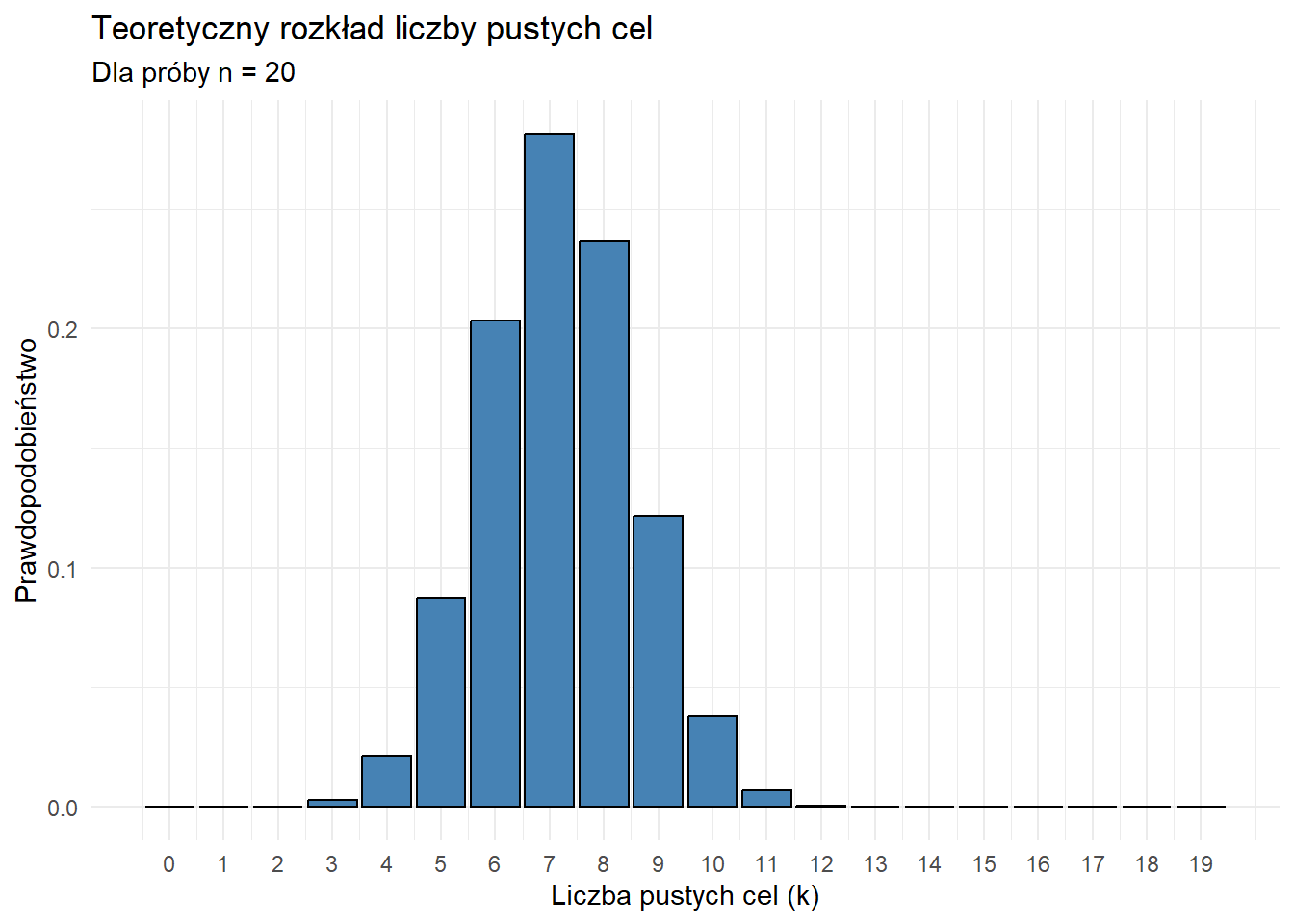
10 9 0.000000001Teoretyczny rozkład statystyki testowej można w przejrzysty sposób zilustrować graficznie. Poniżej zaprezentowano wybrane wykresy, zaczynając od wykresu kolumnowego, który doskonale obrazuje prawdopodobieństwo wystąpienia konkretnej liczby pustych cel dla zadanej liczebności próby.
moja_tabela <- rozklad_davida_hellwiga(20)
ggplot(data = moja_tabela, aes(x = Liczba_pustych_cel_k, y = Prawdopodobienstwo)) +
geom_col(fill = "steelblue", color = "black") +
scale_x_continuous(breaks = moja_tabela$Liczba_pustych_cel_k)+
theme_minimal() +
labs(
title = "Teoretyczny rozkład liczby pustych cel",
subtitle = "Dla próby n = 20",
x = "Liczba pustych cel (k)",
y = "Prawdopodobieństwo"
)
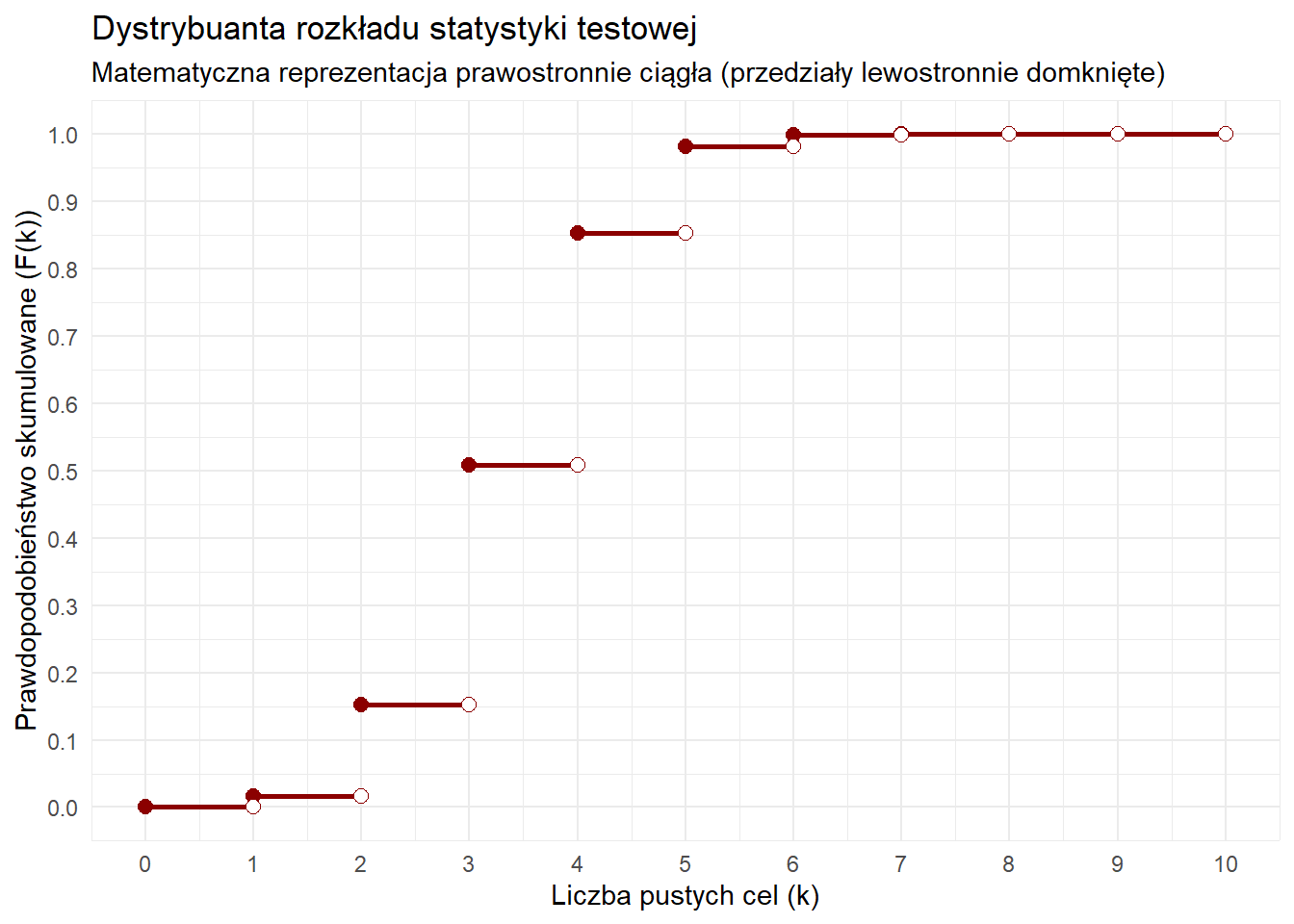
Do stworzenia wykresu dystrybuanty ponownie wspomogę się sztuczną inteligencją. Tym razem zadany prompt to “wygeneruj kod do stworzenia wykresu dystrybuanty”:
moja_tabela <- rozklad_davida_hellwiga(10)
moja_tabela$Skumulowane <- cumsum(moja_tabela$Prawdopodobienstwo)
ggplot(data = moja_tabela) +
geom_segment(aes(x = Liczba_pustych_cel_k,
xend = Liczba_pustych_cel_k + 1,
y = Skumulowane,
yend = Skumulowane),
color = "darkred", linewidth = 1) +
geom_point(aes(x = Liczba_pustych_cel_k, y = Skumulowane),
color = "darkred", size = 2.5) +
geom_point(aes(x = Liczba_pustych_cel_k + 1, y = Skumulowane),
color = "darkred", size = 2.5, shape = 21, fill = "white") +
scale_x_continuous(breaks = 0:10) +
scale_y_continuous(limits = c(0, 1), breaks = seq(0, 1, by = 0.1)) +
theme_minimal() +
labs(
title = "Dystrybuanta rozkładu statystyki testowej",
subtitle = "Matematyczna reprezentacja prawostronnie ciągła (przedziały lewostronnie domknięte)",
x = "Liczba pustych cel (k)",
y = "Prawdopodobieństwo skumulowane (F(k))"
)
Kluczowym i zarazem finalnym etapem każdej procedury testowej jest podjęcie właściwej decyzji statystycznej, polegającej na odrzuceniu hipotezy zerowej lub stwierdzeniu braku podstaw do jej odrzucenia. W klasycznym ujęciu do tego celu wykorzystuje się wyznaczone obszary krytyczne. Jako że w nowoczesnej analityce danych i przy wykorzystaniu narzędzi informatycznych znacznie powszechniejszym standardem jest wnioskowanie na podstawie krytycznego poziomu istotności (p-value), w niniejszym rozdziale skupimy się właśnie na tym podejściu.
W celu zaprezentowania praktycznego zastosowania testu pustych cel posłużymy się środowiskiem R, w którym wygenerowana zostanie sztuczna próba danych, a następnie przeprowadzona na niej procedura weryfikacyjna. Próba losowa o liczebności \(n = 30\) zostanie wygenerowana z rozkładu normalnego o parametrach: średnia równa \(50\) oraz odchylenie standardowe \(10\). Aby uzyskać kod realizujący to zadanie, ponownie wykorzystano model sztucznej inteligencji, stosując następujący prompt: “Wygeneruj kod pozwalający wyznaczyć wartość p dla testu pustych cel z rozkładu normalnego o średniej = 50, odchyleniu = 10 oraz liczebności = 30”.
set.seed(123)
dane <- rnorm(30,50,10)
n <- length(dane)
m <- n
z <- scale(dane)
u <- pnorm(z)
numery_cel <- floor(m * u) + 1
numery_cel[numery_cel > m] <- m
zajete_cele <- length(unique(numery_cel))
K <- m - zajete_cele
tabela_rozkladu <- rozklad_davida_hellwiga(n)
p_value <- sum(tabela_rozkladu$Prawdopodobienstwo[tabela_rozkladu$Liczba_pustych_cel_k >= K])
cat("--- WYNIKI TESTU PUSTYCH CEL ---\n","Liczebność próby (n): ",n, "\n",
"Liczba pustych cel (K): ", K, "\n","Wartość p-value: ", round(p_value, 4), "\n")--- WYNIKI TESTU PUSTYCH CEL ---
Liczebność próby (n): 30
Liczba pustych cel (K): 11
Wartość p-value: 0.5801 Jak można zaobserwować na podstawie powyższego wydruku, przy standardowym poziomie istotności \(\alpha = 0.05\) nie ma podstaw do odrzucenia hipotezy zerowej. Oznacza to, że zachodzi zgodność danych empirycznych z rozkładem normalnym, co potwierdza skuteczność algorytmu dla sztucznie wygenerowanej próby.
W kolejnym kroku sprawdzimy działanie metody na rzeczywistych danych. Do analizy wybrano 15-elementowy zbiór women (wbudowany w pakiety bazowe R), a dokładniej zmienną weight, określającą średnią masę ciała kobiet w wieku 30-39 lat w USA w 1975 roku. data(“women”)
dane <- women$weight
n <- length(dane)
m <- n
z <- scale(dane)
u <- pnorm(z)
numery_cel <- floor(m * u) + 1
numery_cel[numery_cel > m] <- m
zajete_cele <- length(unique(numery_cel))
K <- m - zajete_cele
tabela_rozkladu <- rozklad_davida_hellwiga(n)
p_value <- sum(tabela_rozkladu$Prawdopodobienstwo[tabela_rozkladu$Liczba_pustych_cel_k >= K])
cat("--- WYNIKI TESTU PUSTYCH CEL ---\n","Liczebność próby (n): ",n, "\n",
"Liczba pustych cel (K): ", K, "\n","Wartość p-value: ", round(p_value, 4), "\n")--- WYNIKI TESTU PUSTYCH CEL ---
Liczebność próby (n): 15
Liczba pustych cel (K): 3
Wartość p-value: 0.9929 Otrzymana wartość p-value jest większa od przyjętego poziomu istotności \(\alpha = 0.05\). W związku z tym nie mamy podstaw do odrzucenia hipotezy zerowej, co pozwala przypuszczać, że rozkład wagi w badanej populacji kobiet nie różni się istotnie od rozkładu normalnego.
Weryfikacja jakości procedury statystycznej wymaga oceny jej mocy, czyli prawdopodobieństwa poprawnego odrzucenia fałszywej hipotezy zerowej. Ze względu na złożoność rozkładu dokładnego statystyki liczby pustych cel, do wyznaczenia mocy testu najczęściej stosuje się metody symulacyjne (Monte Carlo). Do przeprowadzenia symulacji ponownie posłużymy się sztuczną inteligencją, zadając jej następujące zadanie (prompt): “Stwórz funkcję pozwalającą wyznaczyć moc tego testu”. Po lekkich modyfikacjach, funkcja pozwalająca na wyliczenie mocy testu Davida-Hellwiga,wygląda następująco.
set.seed(123)
moc=function(n,liczba_symulacji,alfa){
liczba_odrzucen <- 0
tabela_rozkladu <- rozklad_davida_hellwiga(n)
for (i in 1:liczba_symulacji) {
dane_alternatywne <- runif(n, min = 0, max = 100)
z <- scale(dane_alternatywne)
u <- pnorm(z)
m <- n
numery_cel <- floor(m * u) + 1
numery_cel[numery_cel > m] <- m
K <- m - length(unique(numery_cel))
p_value <- sum(tabela_rozkladu$Prawdopodobienstwo[tabela_rozkladu$Liczba_pustych_cel_k >= K])
if (p_value <= alfa) {
liczba_odrzucen <- liczba_odrzucen + 1
}
}
moc_testu <- liczba_odrzucen / liczba_symulacji
cat("--- WYNIKI SYMULACJI MONTE CARLO ---\n")
cat("Liczba symulacji: ", liczba_symulacji, "\n")
cat("Prawidłowe odrzucenia:", liczba_odrzucen, "\n")
cat("Moc testu (1 - beta):", moc_testu * 100, "%\n")
}Wywołajmy powyższą funkcję dla próby o liczebności \(n = 30\) oraz \(1000\) iteracji (symulacji), a następnie powtórzmy procedurę dla większej próby rzędu \(n = 100\). W obu przypadkach przyjmiemy standardowy poziom istotności \(\alpha = 0.05\).
moc(30,1000,0.05)--- WYNIKI SYMULACJI MONTE CARLO ---
Liczba symulacji: 1000
Prawidłowe odrzucenia: 62
Moc testu (1 - beta): 6.2 %Natomiast dla większej liczebności próby \(n=100\):
moc(100,1000,0.05)--- WYNIKI SYMULACJI MONTE CARLO ---
Liczba symulacji: 1000
Prawidłowe odrzucenia: 385
Moc testu (1 - beta): 38.5 %Jak można zaobserwować, wraz ze wzrostem liczebności próby, znacząco wzrosła moc testu.
W niniejszym opracowaniu przedstawiłem zaledwie podstawowe zastosowania testu pustych cel Davida-Hellwiga. Jest to użyteczne narzędzie nieparametryczne, pozwalające na badanie zgodności rozkładu danej próby z rozkładem teoretycznym i stanowiące ciekawą alternatywę dla klasycznych testów statystycznych. Ponadto zaprezentowane wykresy znacząco ułatwiają zrozumienie zasady działania i mechaniki tego testu.
Warto również odnotować, w jak znacznym stopniu wykorzystanie sztucznej inteligencji potrafi usprawnić programowanie w środowisku R. Należy jednak pamiętać – co udowodniły również poszczególne etapy tworzenia tego projektu – że sztuczna inteligencja popełnia błędy. Z tego względu kluczem do skutecznego i rzetelnego prowadzenia analiz umiejętna kontrola generowanych przez nie wyników. Ponadto warto zaznaczyć, że sztuczna inteligencja używana również była w celu sprawdzenia pisowni oraz jej poprawy.
https://dbc.wroc.pl/Content/119110/Domanski_W%C5%82asnosci_testu_Davida-Hellwiga.pdf https://sit.stat.gov.pl/SiT/2025/4/gus_sit_2025_04_grzegorz_ko%C5%84czak_on_a_new_goodness_of_fit_test.pdf PRZEGLAD STATYSTYCZNY R. XII - zeszyt 2- 1965 str. 99-112